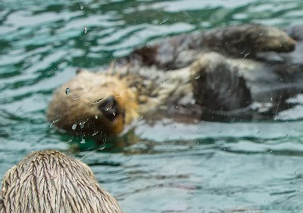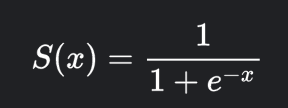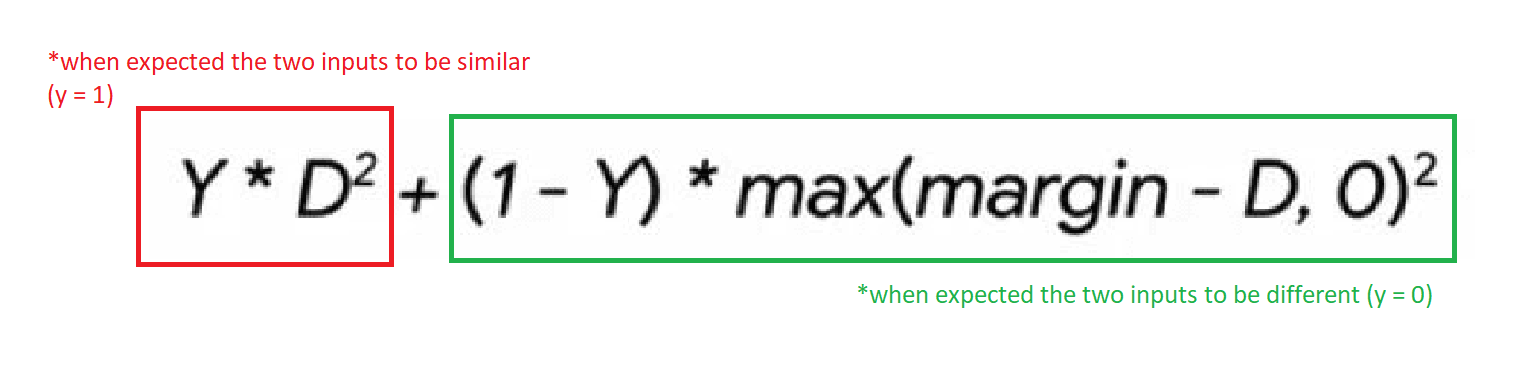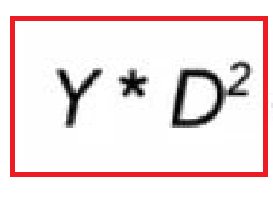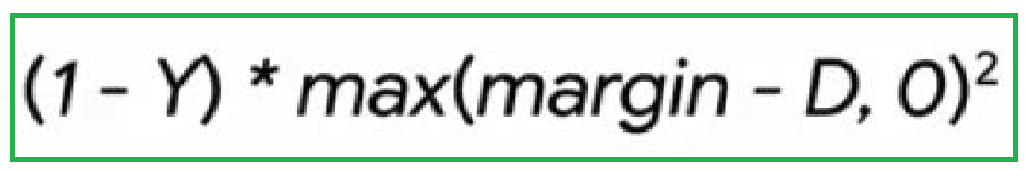Let's say you take a trip to the zoo with a kid. The kid is excited to learn about the various animals in the zoo, their names, and how they look.
The kid sees an otter. She asks you what that animal is called since the kid doesn't know yet that the animal she sees is called an otter.
Instead of telling the kid that the animal is an otter, we show her a chartdetailing all the animals in the zoo.
Next to the image of each animal is the corresponding name of that animal.
The kid compares all the animals in the chart with the one he sees in front of her, deduces that the animal she sees is an otter.
Let's break down the process
Understanding how the kid deduces that the animal is an otter by looking at and comparing each image in the chart is vital to understand the motivation and inspiration behind one-shot and few-shot learning.
Let's say the image the kid sees with her eye is the query image.
So the query image is,
The images in the chart are as follows; let's call the pictures of the chart the support set.
So the support set is as follows,
The kid compares the query image with every image in the support set, and finds out which image is the most similar to the query image.
In her head, she might assign scores to each image in the support set, depending on how well the query image matches with the support set photos.
Then she would pick the image most similar to the query image from the support set, and since the label is right beside the support set image, she knows what that animal is called.
This is the very idea behind one-shot and few-shot learning.
The Main Concepts
In few shot learning, there are 3 main concepts that you should be aware of.
The training set
The support set
The query
The Training set
The training set contains labeled input elements that you use to train the model. For each class (e.g., Husky, Elephant), you have multiple sets of images or inputs so that the model can learn variations of the same input class, which makes the prediction accuracy much higher.
But compared with traditional classification, few-shot learning focuses on understanding the degree of similarity between two images or inputs.
By sampling two random samples from the training set, and labeling them either 1 or 0, depending on if the two samples are similar or different, the model learns to predict how similar those two images are.
The model tries to learn a similarity function by comparing two images at a time with the training set, whereas you can see in the above image when comparing two input images, the model can predict how similar two huskies are, giving it a score of 0.8, which means the model knows that the two images have the same context.
However, when the model is given two images that aren't similar in context (i.e., husky and elephant), the model gives it a similarity score of 0.2, which is low, meaning those two images aren't similar to one another.
The Support set
The support set is used to help make a prediction.
The model that has learned a suitable similarity function can now compare the query image with every given image in the support set and assign scores, a higher score if the model thinks that the query image and the image from the support set are similar.
Then once the model compares all given images in the support set, the prediction is whatever input class that has the highest similarity score with the query image.
The Query
The query input is the input that we provide to the model to predict its class.
The query input is then compared with every sample in the support set, and via the similarity function, the model learned can use to determine the scores of how well the query matches with each sample in the support set.
The sample with the highest score is picked as the final prediction, and the name of the class of that selected sample is the final classification class.
So in the following example, if we use the 'rabbit' image as the query image, then the query would have the highest similarity score with the 'rabit' sample image in the support set, so the final prediction would be 'rabbit.'
Training Models to Detect Similarity Using Siamese Networks
A commonly used machine learning neural net model that performs similarity prediction is a Siamese Network.
It's named because the architecture of the network resembles Siamese twins.
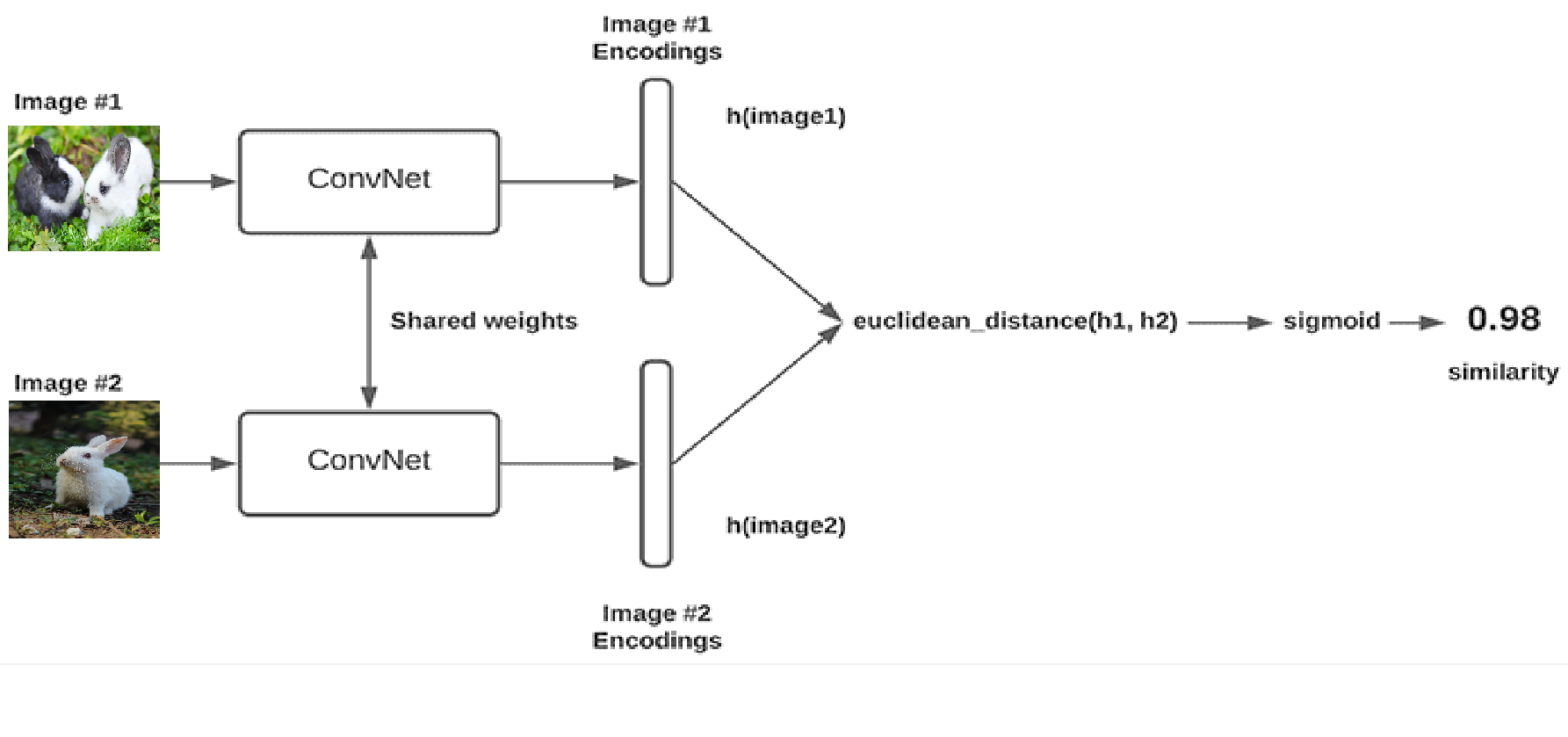
The below image depicts a Siamese network.
In the above diagram, the inputs are two rabbit images. The output of the network is a similarity score of 0.98, which means the network has predicted that those two images are from the same class and thus similar.
The inputs are first fed into a convolutional neural network, where the networks have the same weights and biases (shared weights & biases).
The output of the convolutional neural network is a vector representation of the input images, called h(image1) and h(image2), where image1 and image2 are inputs, and 'h' is the convolutional neural network function.
Once you have vector representations of the images, then you can use a distance metric, like Euclidean distance, to measure how far apart these two vectors lie on the projected plane.
The idea here is that if the two images are alike, then they are close to each other, but if the two images are far apart (e.g., an image of a rabbit and an image of a dog), then the vectors would be far away from each other.
Once we get the distance metric, we squash the scalar value via a sigmoid function to a range between 0 and 1.
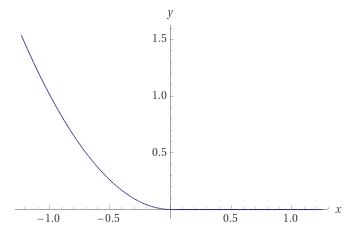
A sigmoid function is as follows,
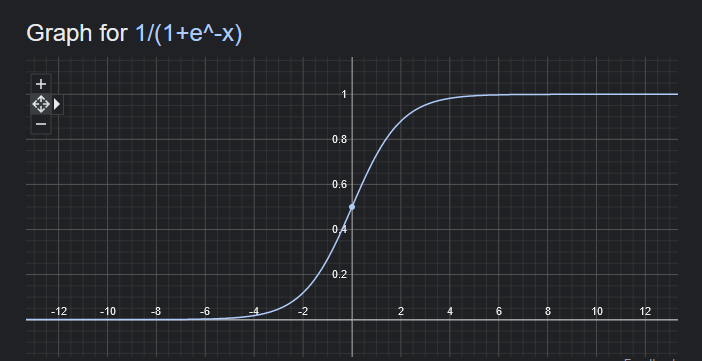
The graph of the sigmoid function looks like this,
As you can see in the above graph, the distance metric, once plugged into the sigmoid function, would be squashed to a value between 0 and 1.
To train this type of network, we use a "contrastive loss" function
The Contrastive Loss Function
Contrastive Loss is a metric-learning loss function introduced by Yann Le Cunn et al. in 2005 in the paper "Dimensionality Reduction by Learning an Invariant Mapping."
A contrastive loss function is a perfect fit to train a Siamese network because the goal of a Siamese network isn't to classify an input but rather to differentiate between two given inputs.
The above is the formulae that describe contrastive loss.
We can break this formula down into smaller chunks so that we can easily understand what's going on.
The formulae are of two parts, as shown in the below diagram.
Notice that Y is the desired outcome of the network.
If the two inputs are similar, we expect the network to output a value close to one or one.
If the two inputs are different, we expect the network to output a value that's closer to zero or zero.
When Y is equal to one, then the green part of the formulae can be ignored, as it cancels to zero. (1 - 1) = 0.
When Y is equal to zero, then the red part of the formulae can be ignored as it cancels to zero (0*D^2 = 0).
So depending on the context, the contrastive loss function changes to evaluate how well the network performed.
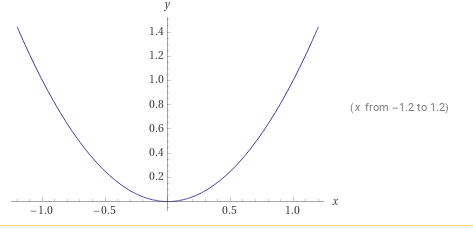
If we plot the red part of the formulae on a graph, we get a normal quadratic graph.
Notice that the minimum of this graph is when D (or x) is zero.
This means if the inputs are similar, to get the minimum loss, the distance (D) between the two embedded vectors (vector representations of the inputs) must be close to one another, or the distance between those two vectors must be almost zero.
However, when you plot the green part of the contrastive loss formulae, you get the following graph.
This part of the formulae is a max function.
It is the maximum between either a difference between a margin (M) minus the distance between the two vector representations of the input or zero, squared.
It means that if the distance between the two vectors is greater than a predefined margin, that means the network performed well, and the loss is zero.
However, if the two vectors are close-by, then the network performs poorly. Because if you have two different inputs, the idea here is that your network must try to differentiate them, and say that they are different, so the vectors need to be as far away from each other as possible.
The margin (M) is a hyperparameter of the Siamese network.
Using this loss function, you can now use backpropagation to find the gradients of the weights and biases in the network, and using gradient descent, the network can be trained so that the network converges to minimize the contrastive loss function.
Triplet Loss
The idea behind triplet loss is to train a neural network to learn good representations of input data such that similar inputs are mapped close to each other and dissimilar inputs are mapped far apart from each other in a learned feature space.
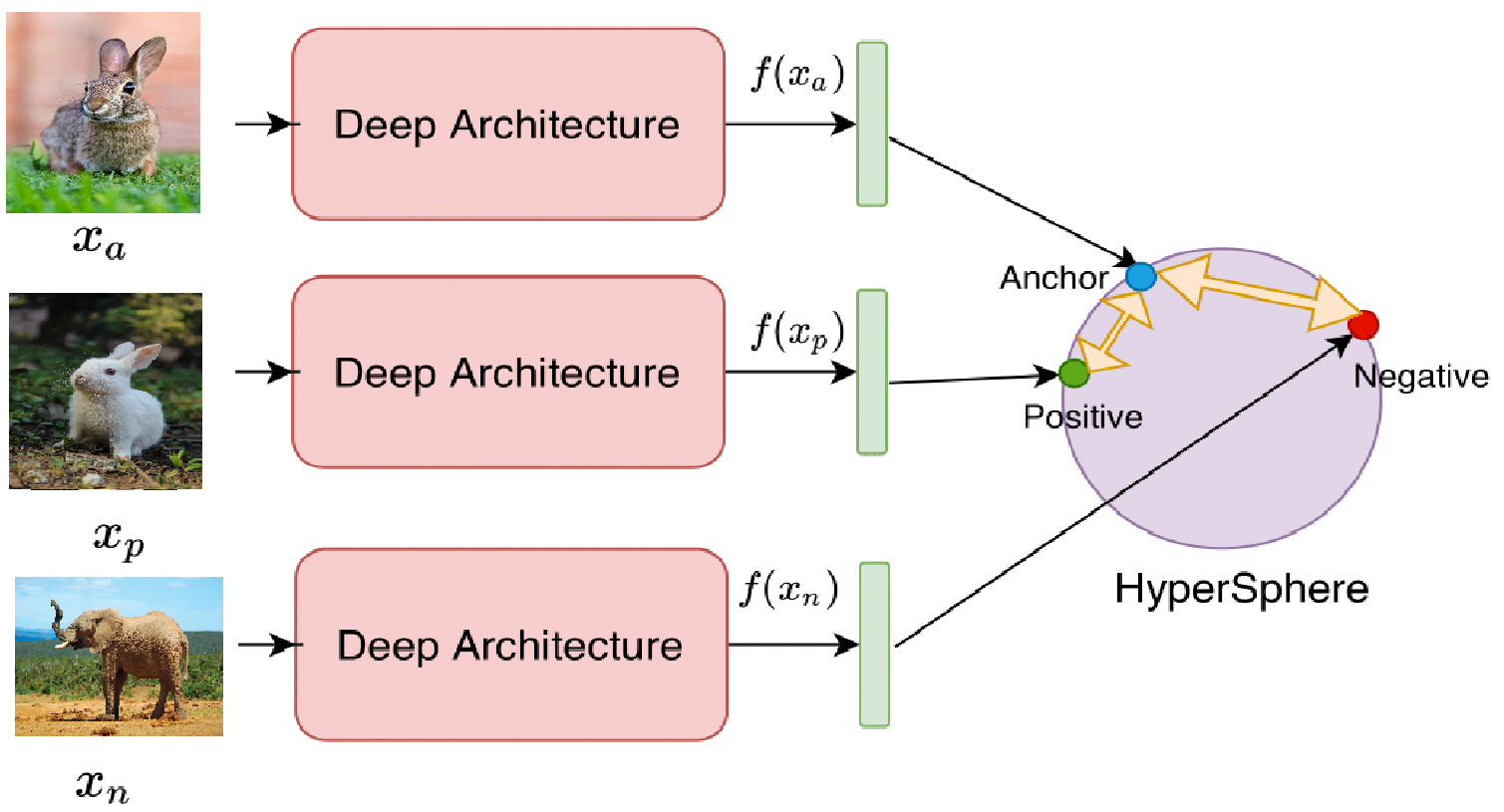
The triplet loss function takes in three inputs: an anchor input, a positive input, and a negative input.
The anchor and positive inputs are samples from the same class, while the negative input is a sample from a different class.
The goal of triplet loss is to minimize the distance between the anchor and positive inputs while maximizing the distance between the anchor and negative inputs.
This encourages the network to learn features that can distinguish between similar and dissimilar inputs.
Formally, let \(X_a\), \(X_p\), and \(X_n\) be an anchor, positive, and negative sample, respectively.
Let \(d(X_a, X_p)\) be the Euclidean distance between the anchor and positive samples and \(d(X_a, X_n)\) be the Euclidean distance between the anchor and negative samples.
where margin is a hyperparameter that specifies the minimum desired difference between the distances.
The loss is zero when the distance between the anchor and negative samples is greater than the distance between the anchor and positive samples plus the margin.
Otherwise, the loss is positive and the network is encouraged to update its parameters to increase the margin.
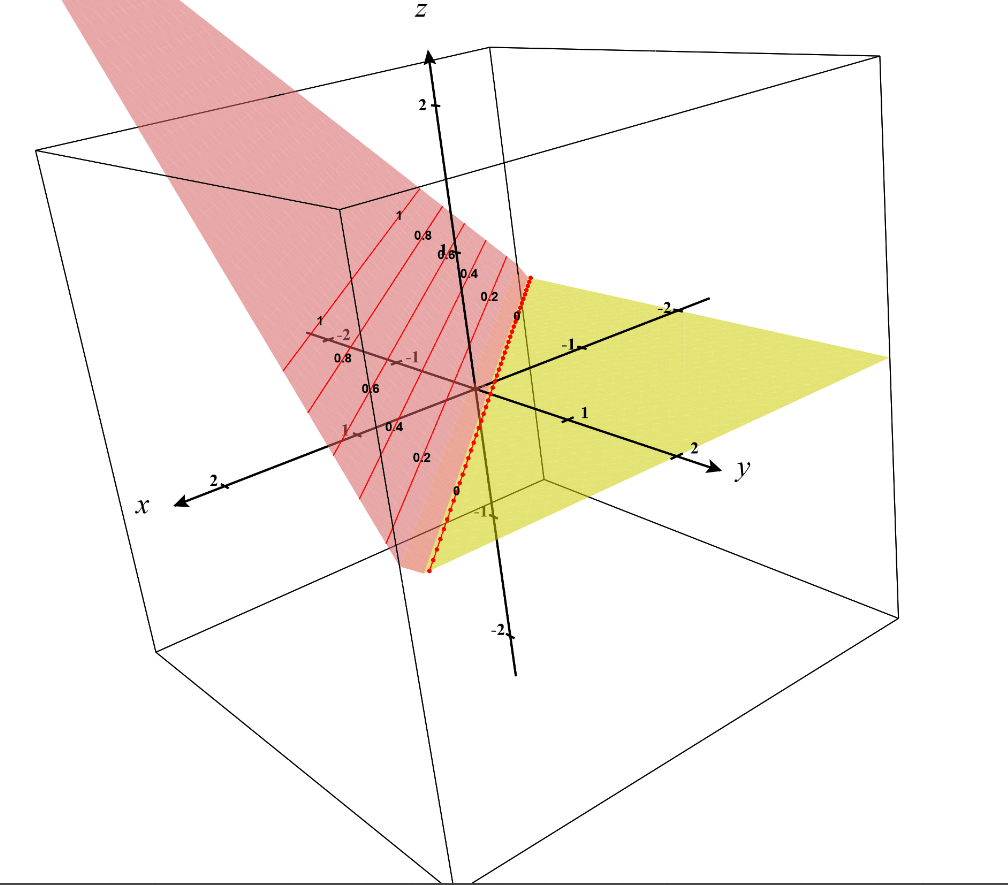
When you plot the loss function, it looks like this,
Notice in the above graph \( x = d(X_a, X_p) \) and \( y = d(X_a, X_n) \) respectively.
When the distance between the positive sample and the anchor decrease, and the distance between the negative sample and the anchor increase, the loss is flat, meaning its minimum.
However, if the opposite happens, then the loss increases.
This is the intuition behind triplet loss.
I hope you enjoyed reading this article on few-shot classifiers.
In a future article, I will be diving much deeper into this topic of research in the field of Machine Learning.
Thanks for reading!
References
Shushen Wang's lecture series on Few Shot Learning Part 1 and 2.